生物信息学
2.1 生物信息学中的统计知识概览
桂松涛 Blog
songtaogui@163.com

统计方法导览
|
|
|
|
从正态分布开始
从正态分布开始
正态分布(Normal distribution)/高斯分布(Gaussian distribution)
|
正态分布是一种连续型随机变量概率分布, 分布图是一条以均值为中心, 左右对称的钟形曲线。 若随机变量\(X\)服从一个平均数为\(\mu\) (mu) 、标准差为\(\sigma\) (sigma) 的正态分布,则记为:
\(X \sim N(\mu,\sigma^2)\)
其概率密度函数为: \( f(x) = \frac1{\sigma\sqrt{2\pi}}\; \exp\left(-\frac{\left(x-\mu\right)^2}{2\sigma^2} \right) \! \) |
 |
从正态分布开始
模拟正态分布抽样的频率直方图
从正态分布开始
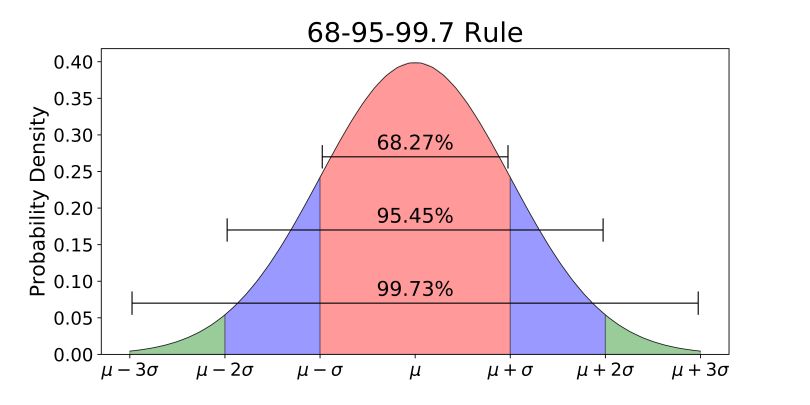
为什么正态分布这么重要?
 |
|
|
从正态分布开始
为什么正态分布无处不在: 中心极限定理(Central Limit Theorem)
数据描述和数据清洗
数据描述
|
|
|
数据描述
|
mean, median, mode, skew 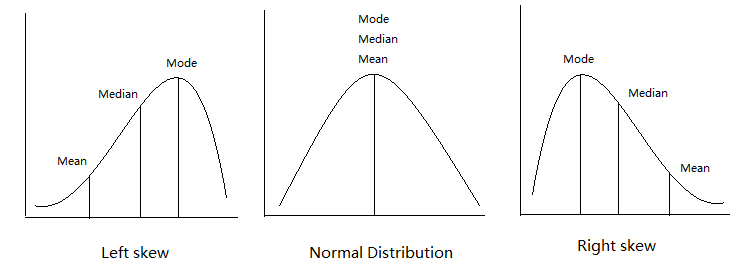
|
kurtosis 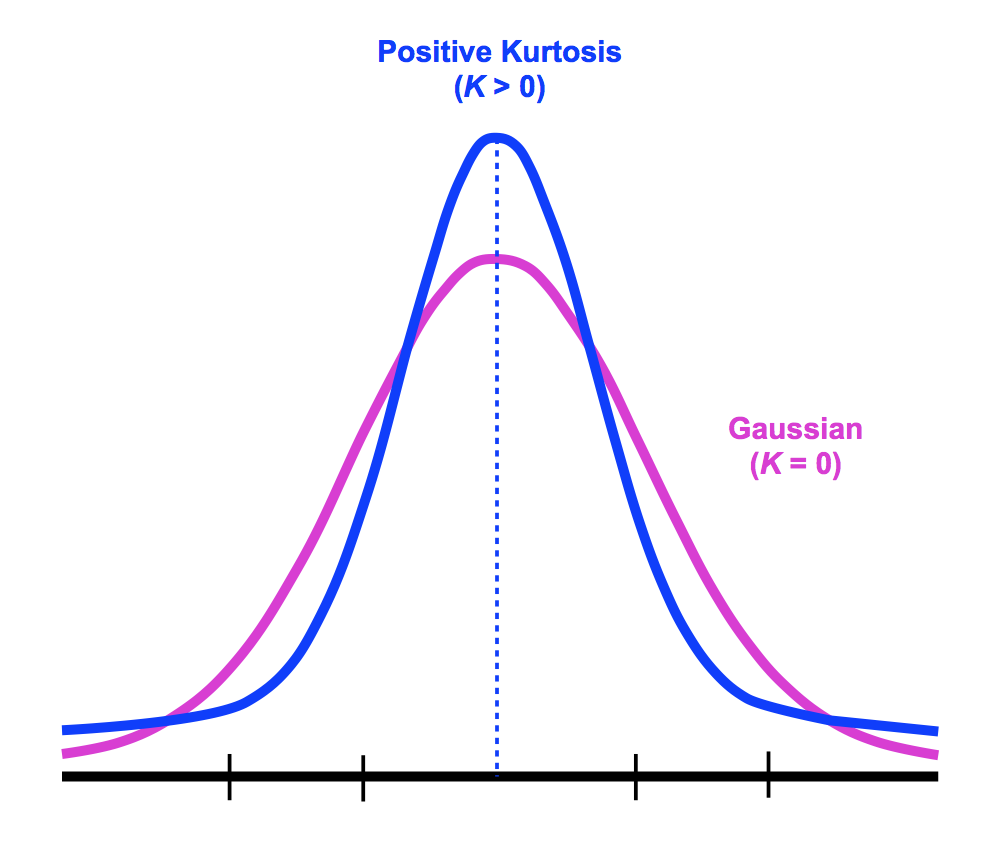
|
数据清洗-缺失值处理
|
|
数据清洗-缺失值处理
|
|
|
数据清洗-缺失值处理
数据清洗-异常值处理
统计水稻籽粒颜色
[黄, 黄, 白, 黄, 黑, 黑, 黄, 白, 白, 12cm, 锟斤拷]
统计班中男性身高(cm)
[2.29, 165.0, 166.9, 169.3, 170.9, 172.1, 173.4, 173.4, 174.0, 177.1, 209.1, 215.2, 1755]
基因在群体中的表达量(FPKM)
[0.1, 0.2, 0.1, 1.1, 1.5, 1.8, 3, 4, 10, 2000, 5000]
SNP与表型的关联程度(P-value)
[ 1, 0.9, 0.9, 0.8, 1, 0.5, 0.5, 0.3, 0.1, 0.0001, 1E-7, 1E-15 ]
数据清洗-异常值处理
数据清洗-异常值处理
数据清洗-异常值处理
图形法: 直方图
在直方图上,位于图形两端,并远离均数的数值,提示可能存在异常
数据清洗-异常值处理
图形法: 箱线图
在箱线图上位于上下四分位数±1.5倍四分位间距的数值,提示可能存在异常
数据清洗-异常值处理
统计法: \( outlier ≈ \bar{X} ± 3*STD \)
|
|
数据清洗-异常值处理
数据清洗-数据缩放转换
规范化(Normalization)
标准化(Standardization)
归一化
中心化(Zero-Centered)
正态化(Normal transform)
正则化...
数据清洗-数据缩放转换
为什么需要数据缩放转换?
GDP(亿, 百亿) => 标准化
统一分析标准 :
发病率, 存活率, 病毒抗药性, 药物抗病性, ... => 正/负向化
符合统计模型假设 :
T-Test, 线性回归等要求符合正态分布 => 正态化
数据清洗-数据缩放转换
规范化(Normalization) :
将不同变化范围的值映射到相同的固定范围中,常见的是[0,1],此时亦称归一化
最常用方法: min-max normalization
\( X^{new} = \frac{X - X_{min}}{X_{max} - X_{min}}\)
去量纲化 , 尺度(scale)统一 , 不改变原排序 , 但不能处理异常值
|
|
|
数据清洗-数据缩放转换
标准化(Strandardization) :
将数据转换为均值为0, 标准差为1的新数据, 最常用的方法为
z-score标准化z-score normalization
\( X^{new} = \frac{X - μ}{δ}\)
去量纲化 , 不改变原排序 , 能处理异常值 , 尺度(scale)不统一
数据清洗-数据缩放转换
正态化(Normal transformation) :
将非正态分布的数据转换为正态/近似正态分布
数据清洗-数据缩放转换
正态化(Normal transformation)
数据清洗-数据缩放转换
针对特定分析开发特定的标准化算法
|
RNA-Seq Reads Count的标准化
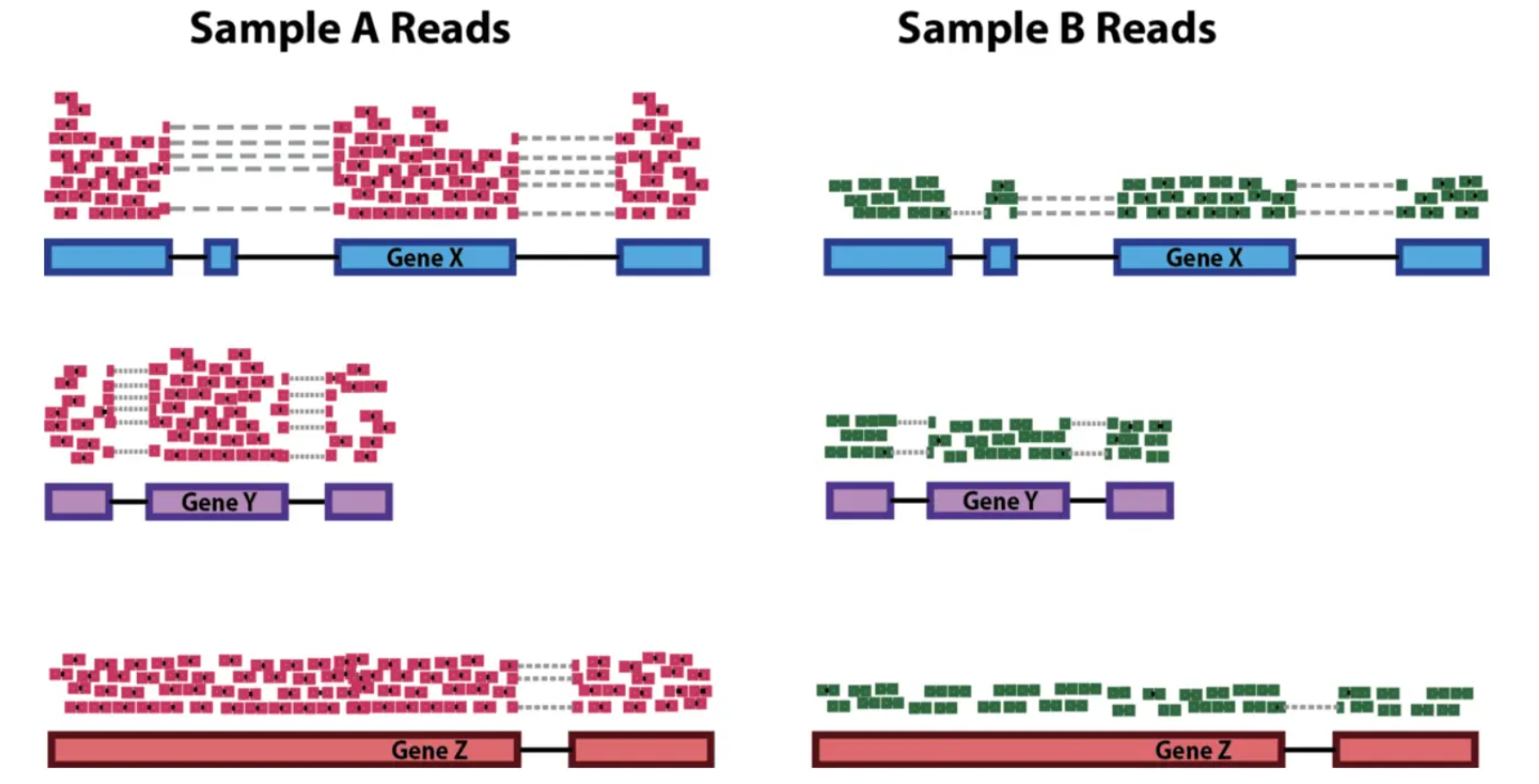 |
\( CPM = \frac{A * 1E6}{G} \) \( RPKM/FPKM = \frac{A * 1E6}{G * L_A / 1000} \) \( TPM = \frac{RPK_A * 1E6}{\sum{(RPK_A)}} \quad where \quad RPK_A = \frac{A}{L_A / 1000}\) |
差异分析: 以T-TEST为例
T-TEST
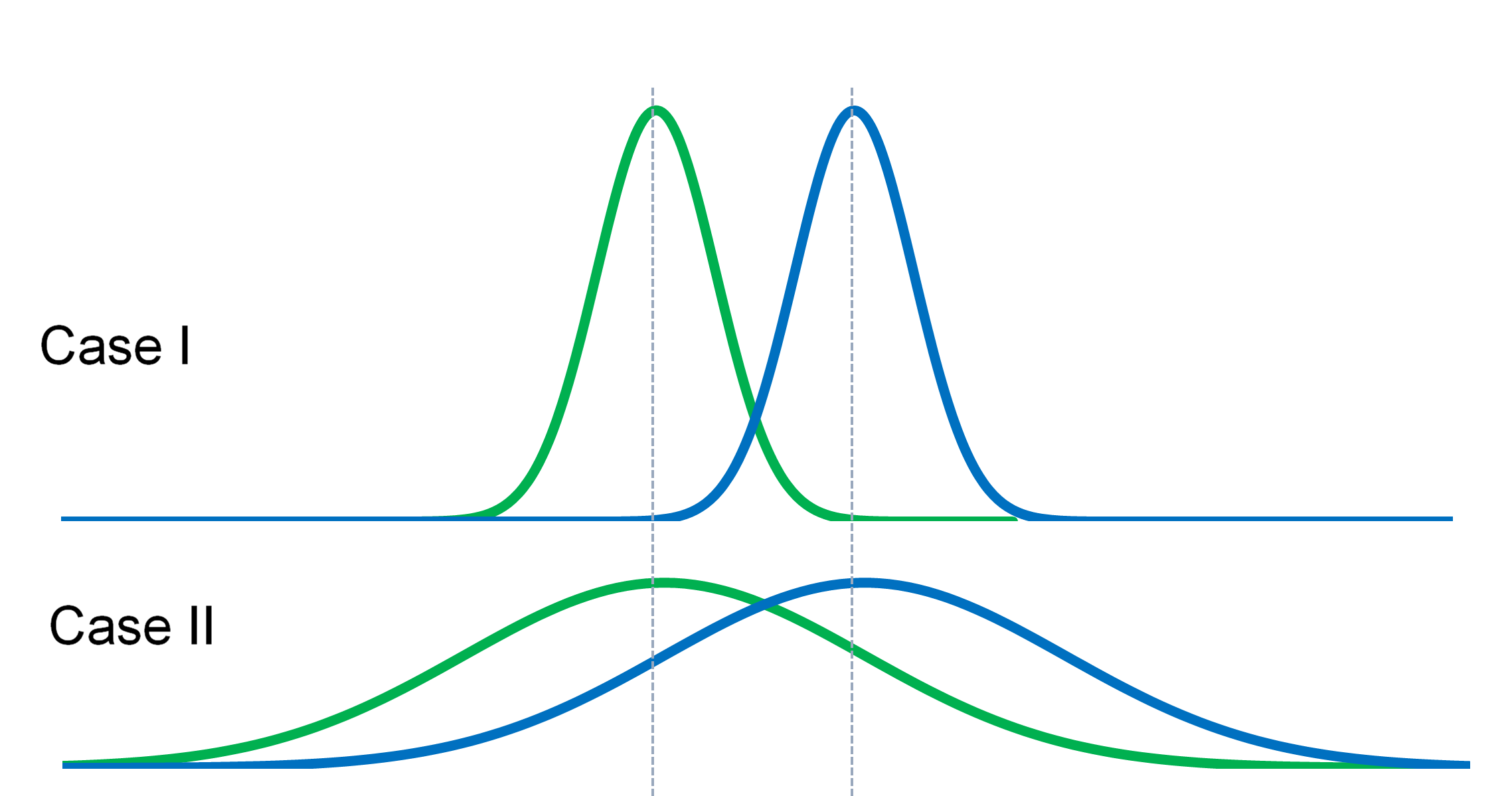 |
T-TEST
T-TEST的适用条件
观察变量为连续变量;
观察变量相互独立;
观察变量不存在显著异常值;
观察变量为(或近似为)正态分布;
观察变量最多两组;
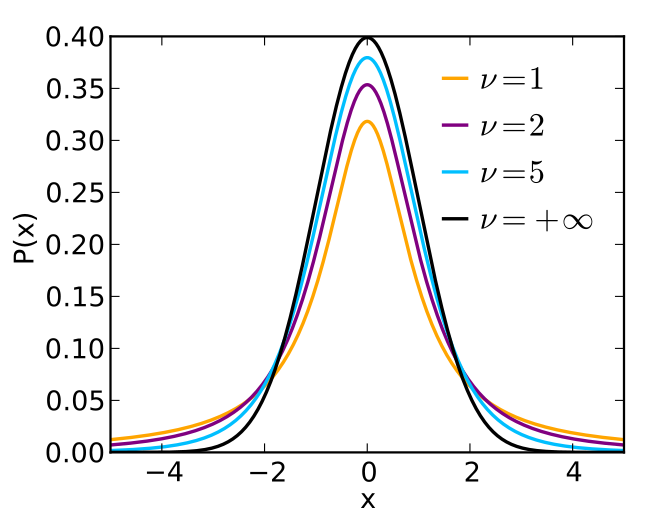
T-TEST
T-统计量的计算
|
T统计量(以单样本T-Test为例)
\(t = \frac{X̄ - μ}{s / \sqrt{n}}\) T分布  其中ν为自由度 拓展阅读: 什么是自由度
|
|
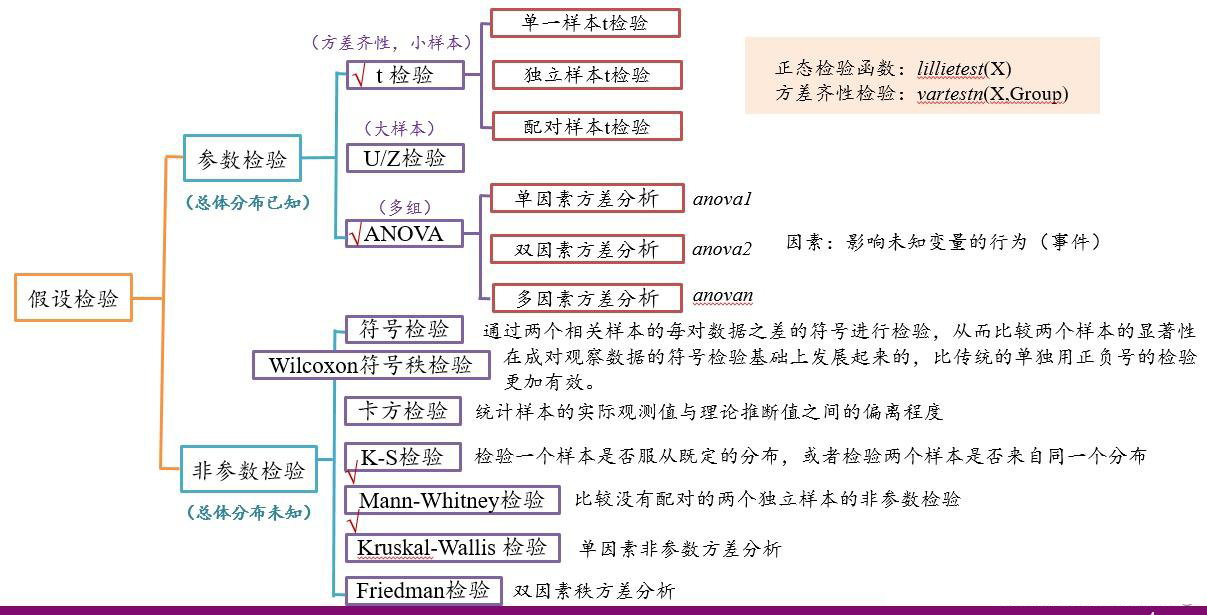
参数检验和非参数检验方法