Gst Group Training
001 整洁数据分析
桂松涛 Blog
songtaogui@163.com

2025-12-18
什么是数据分析
 "已经连续开了十次大了,这次压小绝对一波回本!
|
"数据分析,就是通过收集、整理、加工和解释数据,从中提取有用的信息和规律,帮助我们做出更好的决策" 明确问题 > 收集数据 > 数据清洗 > 数据挖掘 > 结果呈现
|
如何做数据分析
if the only tool you have is a hammer, to treat everything as if it were a nail.
– Abraham Maslow
– Abraham Maslow
 |
|
|
如何做数据分析
基于编程语言的数据分析工具

|
|
向量化
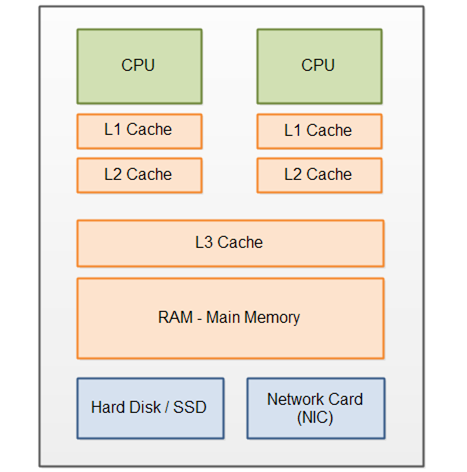
|
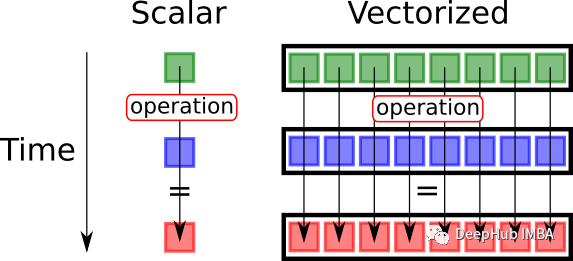
|
函数式
常见编程范式: 命令式、面向对象、函数式
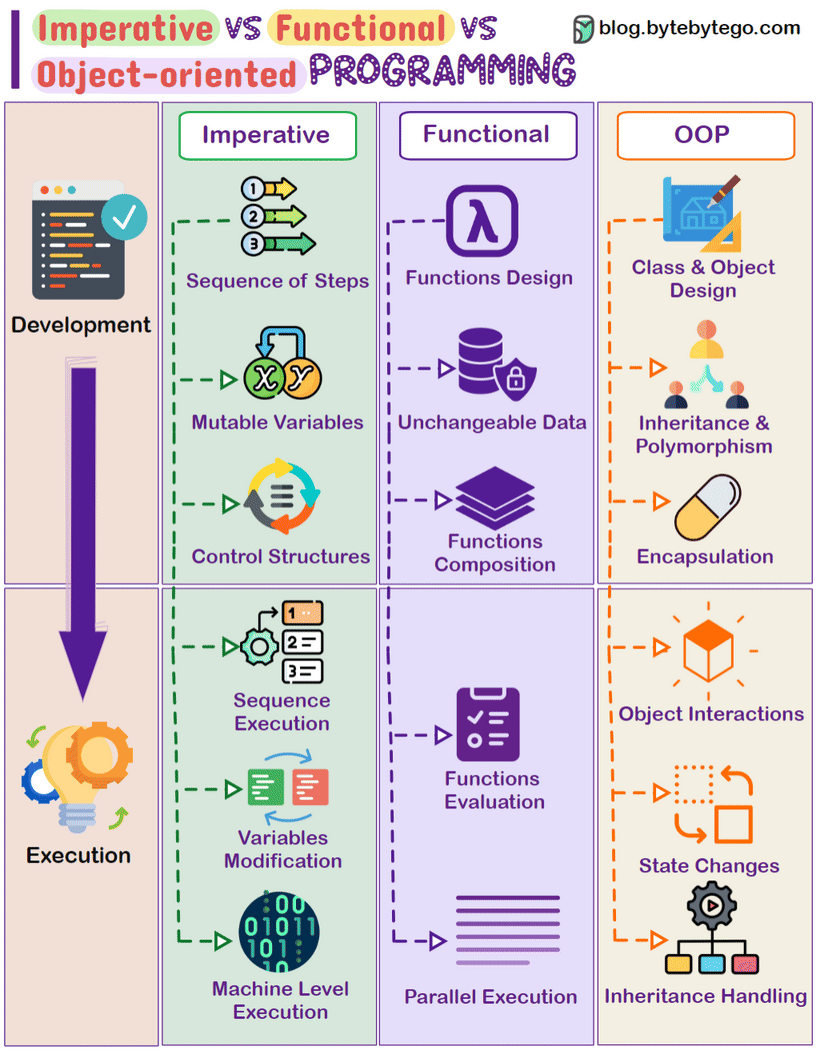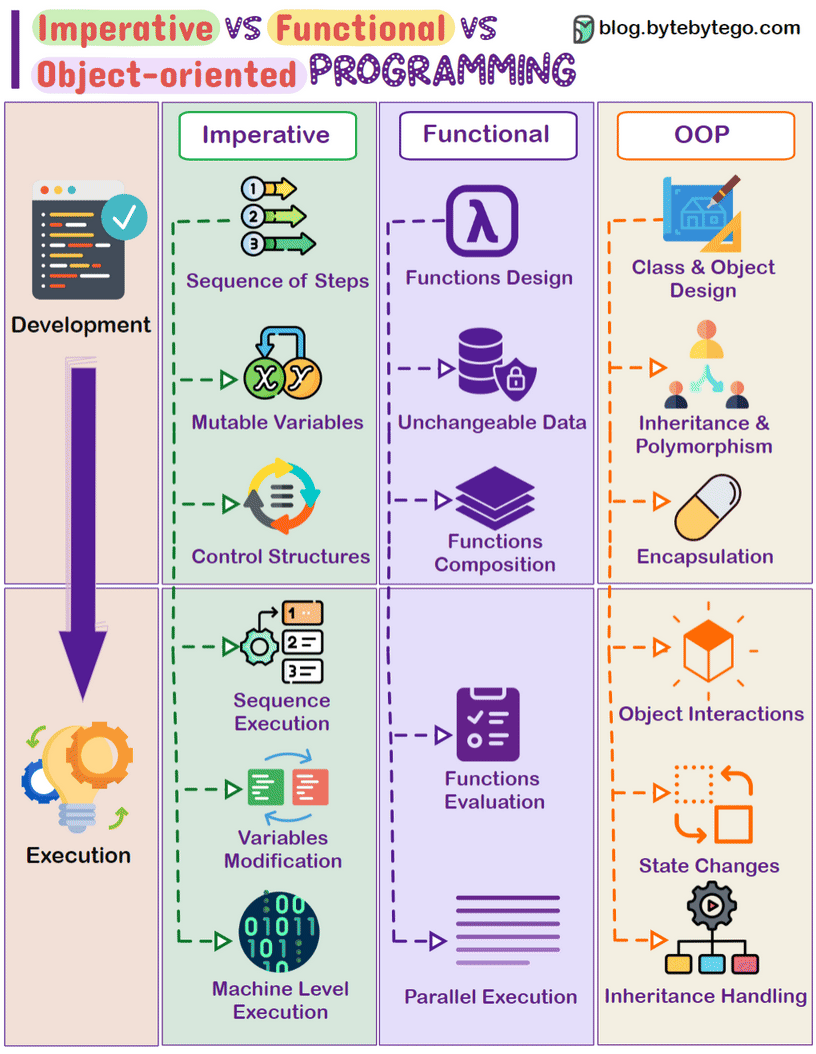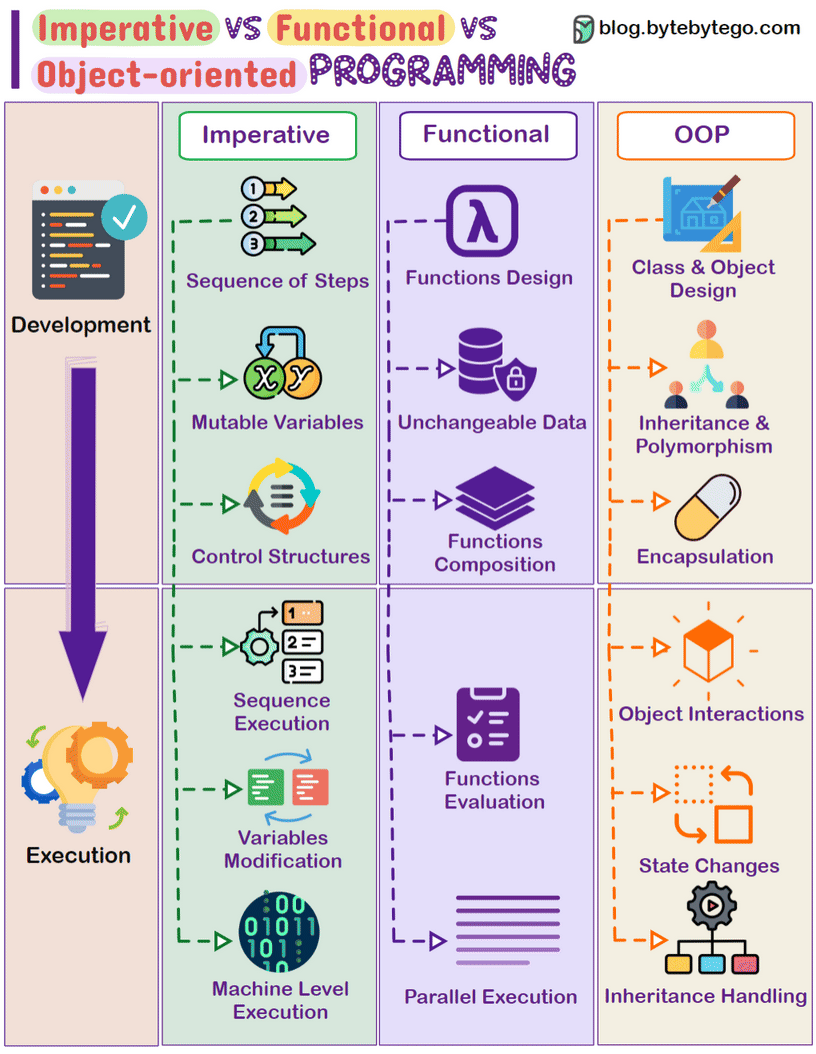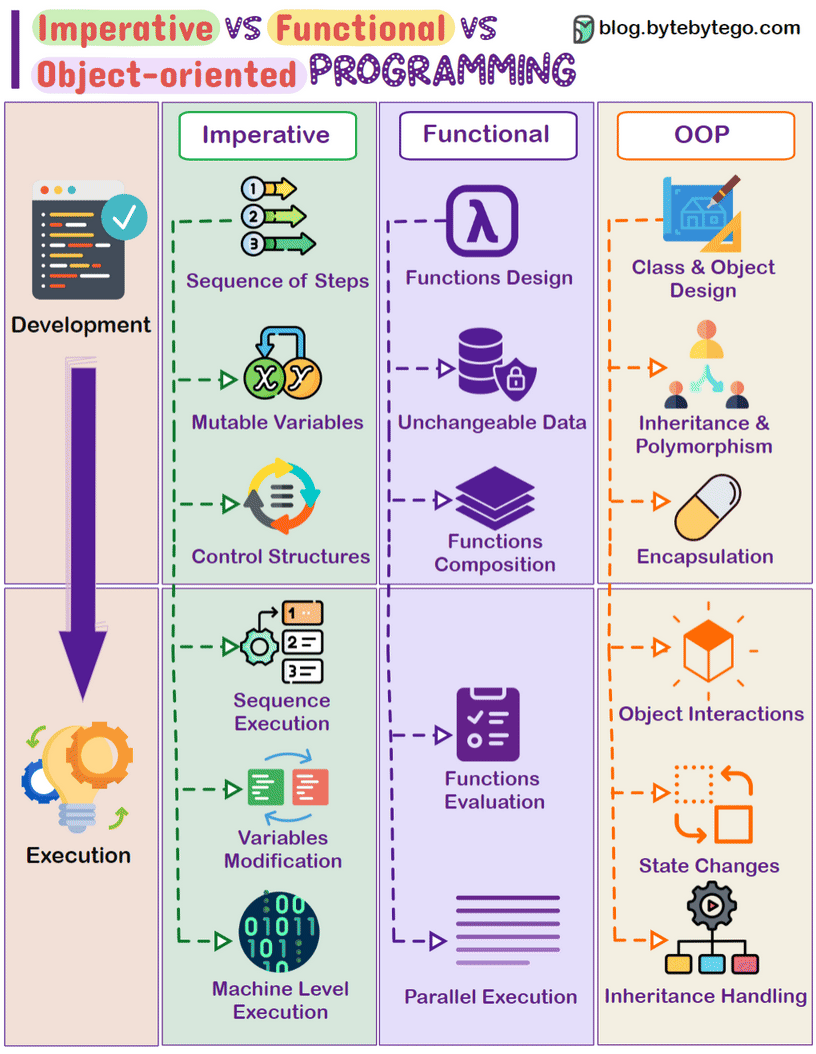
|
任务: 给定一个数字列表,计算其中所有“偶数”的“平方”之“和”: \([1, 2, 3, 4, 5, 6] => 2^2 + 4^2 + 6^2 = 56\) |
函数式
常见编程范式: 命令式、面向对象、函数式
|
|
任务: 给定一个数字列表,计算其中所有“偶数”的“平方”之“和”:
\([1, 2, 3, 4, 5, 6] => 2^2 + 4^2 + 6^2 = 56\)
|
函数式
常见编程范式: 命令式、面向对象、函数式
|
|
任务: 给定一个数字列表,计算其中所有“偶数”的“平方”之“和”:
\([1, 2, 3, 4, 5, 6] => 2^2 + 4^2 + 6^2 = 56\)
|
函数式
常见编程范式: 命令式、面向对象、函数式
|
|
|
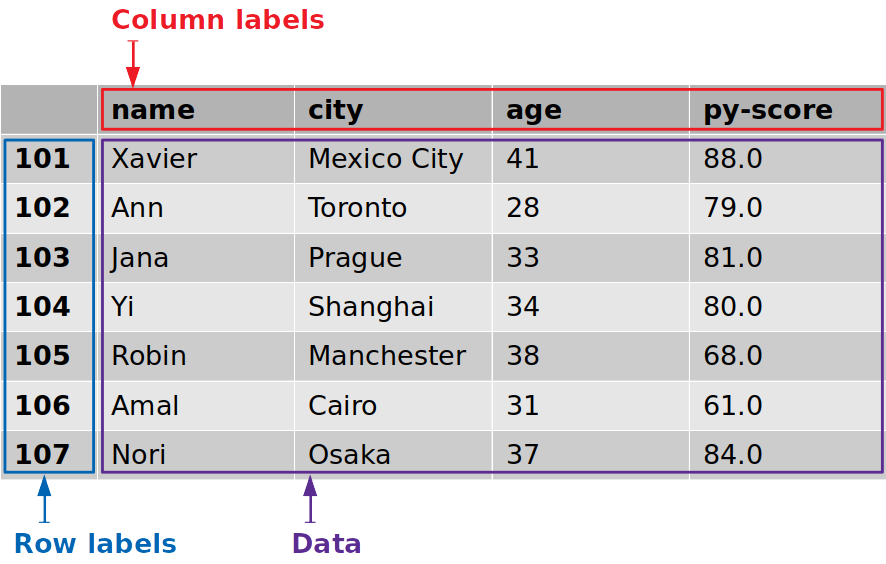
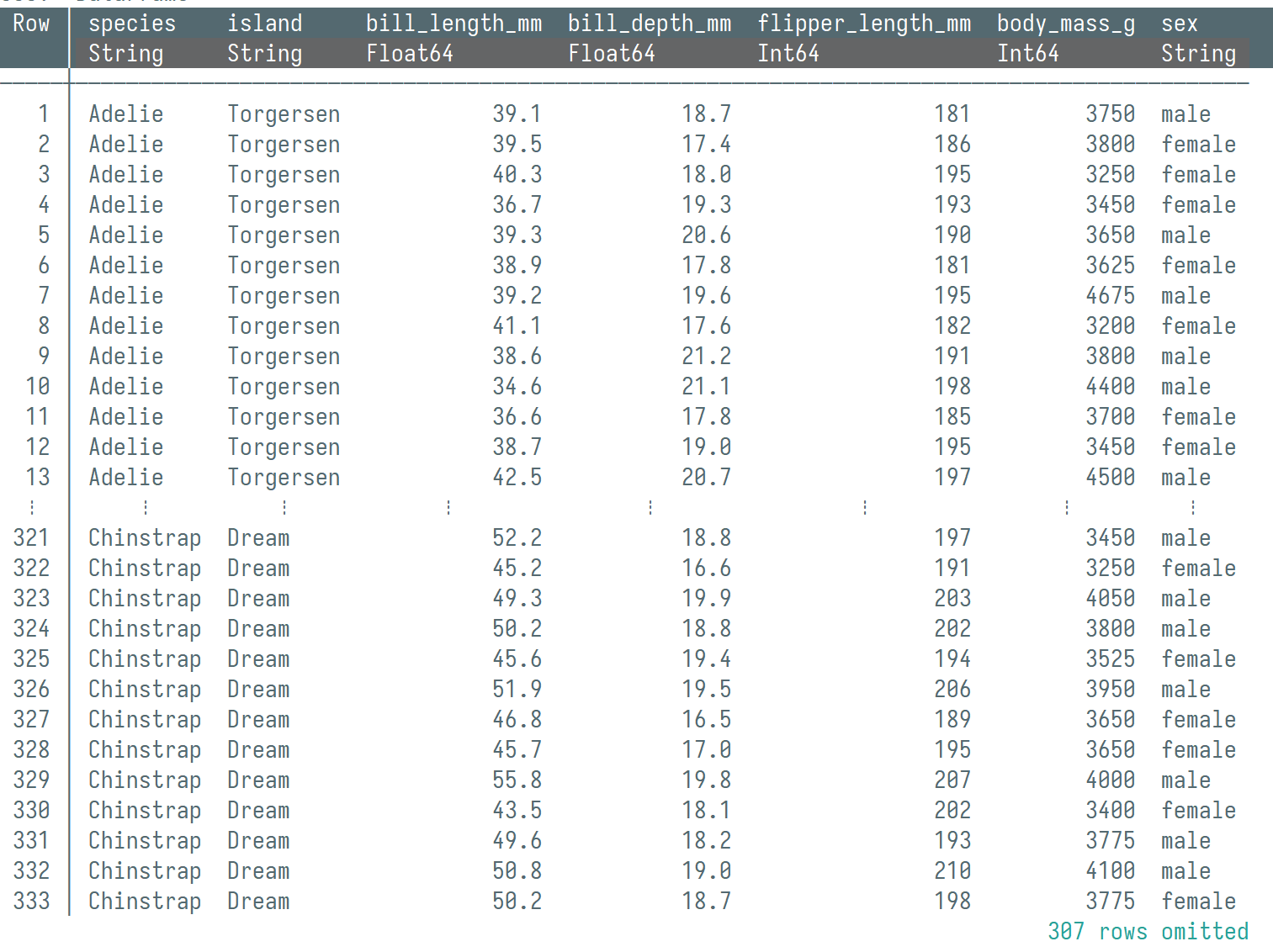
Dataframe数据结构
Dataframe: 基于向量化 + 函数式的数据分析
|
|
Dataframe的基本操作
|
构建、导入
|
基本操作: 选择、过滤、基本信息
|
Dataframe的进阶操作
连接: join
|
|
innerjoin(df1, df2, on = :ID) # 大部分join都用同一种语法
innerjoin(df1, df2, on = :ID_df1 => :ID_df2) # 如果要合并的列名字不一样, 用`=>`指示对应关系
crossjoin(df1, df2, makeunique = true) # crossjoin不使用`on`关键词重塑: 长宽表转换 –> 整洁数据
|
|
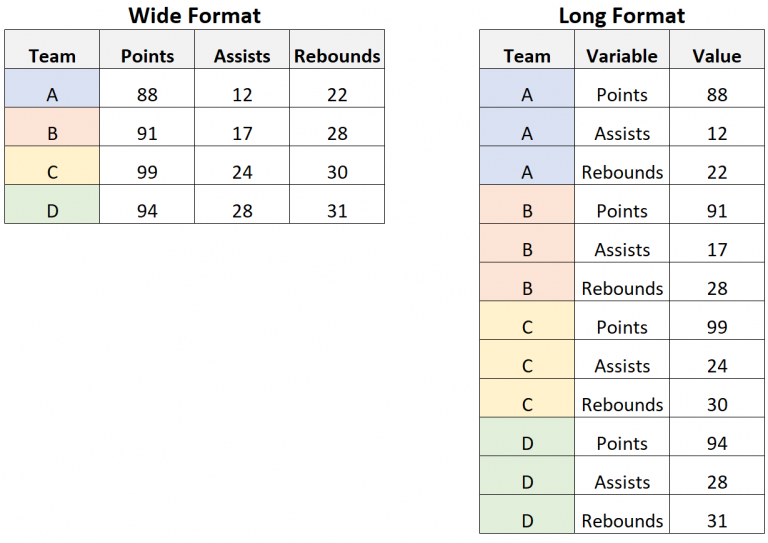
重塑: 长宽表转换 –> 整洁数据

筛选
Select: 复杂的按列过滤select(df, Not(:x1))
select(df, r"x")
select(df, :x1 => :a1, :x2 => :a2) # 重命名列
select(df, :x1, :x2 => (x -> x .- minimum(x)) => :x2) # 更改x2的数值
select(df, :x2, :x2 => ByRow(sqrt)) # 生成新的名为:x2_sqrt的列, 存放x2列的开平方值
select(df, AsTable(:) => ByRow(extrema) => [:lo, :hi]) # 逐行计算所有列的极值, 存到:lo :hi两列中修改
transform: 变换julia> df = DataFrame(x1=[1, 2], x2=[3, 4], y=[5, 6])
2×3 DataFrame
Row │ x1 x2 y
│ Int64 Int64 Int64
─────┼─────────────────────
1 │ 1 3 5
2 │ 2 4 6
julia> transform(df, All() => +)
2×4 DataFrame
Row │ x1 x2 y x1_x2_y_+
│ Int64 Int64 Int64 Int64
─────┼────────────────────────────────
1 │ 1 3 5 9
2 │ 2 4 6 12修改
transform: 变换julia> using Statistics
julia> df = DataFrame(x=[1, 2, missing], y=[1, missing, missing])
3×2 DataFrame
Row │ x y
│ Int64 Int64
─────┼──────────────────
1 │ 1 1
2 │ 2 missing
3 │ missing missing
julia> transform(df, AsTable(:) .=>
ByRow.([sum∘skipmissing,
x -> count(!ismissing, x),
mean∘skipmissing]) .=>
[:sum, :n, :mean])
3×5 DataFrame
Row │ x y sum n mean
│ Int64 Int64 Int64 Int64 Float64
─────┼─────────────────────────────────────────
1 │ 1 1 2 2 1.0
2 │ 2 missing 2 1 2.0
3 │ missing missing 0 0 NaN排序
sort 和 order
sort!(iris) # 每列都逐级参与排序
sort!(iris, rev = true)
sort!(iris, [:Species, :SepalWidth]) # 指定排序的列
sort!(iris, [order(:Species, by=length), order(:SepalLength, rev=true)]) # 指定排序方式
sort!(iris, [:Species, :PetalLength], rev=[true, false]) # 另一种指定排序方式的语法管道、向量化、函数式
using Statistics
df = DataFrame(a = repeat(1:5, outer = 20),
b = repeat(["a", "b", "c", "d"], inner = 25),
x = repeat(1:20, inner = 5))
# df
# Row │ a b x
# │ Int64 String Int64
#─────┼──────────────────────
# 1 │ 1 a 1
# 2 │ 2 a 1
# 3 │ 3 a 1
# 4 │ 4 a 1
# 5 │ 5 a 1
# 6 │ 1 a 2
x_thread = @chain df begin
@transform(:y = 10 * :x)
@subset(:a .> 2)
@by(:b, :meanX = mean(:x), :meanY = mean(:y))
@orderby(:meanX)
@select(:meanX, :meanY, :var = :b)
endSplit-Apply-Combine
不同编程语言的Dataframe实现
Python/Rust: polar >> pandas
R: data.table >> dataframe
Julia: Dataframes.jl
Linux命令行下类似Dataframe的操作
awk or perl one-liner
groupby of bedtools
csvtk